这两天跟人讨论起说在DL中用DBN的,而DBN就是用很多RBM叠加起来的,想起以前看到的RBM,只是粗略看了下,没有仔细研究,
现在正好借这个机会好好研读一番。
玻尔兹曼机(BM):
波尔兹曼机(Boltzmann Machine, BM)是Hiton(是的,Hiton大牛)和Sejnowski 于1986年基于统计力学提出的神经网络,这种网络中的神经元是随机神经元,神经元的输出只有两种状态(激活和未激活),一般用二进制0或1表示。如下图所示:

受限玻尔兹曼机(RBM):
BM具有强大的无监督学习能力,能够学习数据中复杂的规则。但是训练时间过长,另外其概率分布很难获得,为了克服这一个问题,Smolensky引入一个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM),如下图所示:

可以看到,隐层和可见层在层内是无连接的。这样,当给定了可见层状态时,隐层个单元的激活状态是相互独立的,反之,给定隐层状态,各可见层单元的状态也是相互独立的。这样可以用Gibbs采样逼近其概率分布。
前面说到,BM是基于统计力学来的,首先介绍其能量函数:
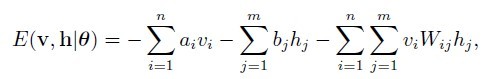
这里,v和h代表可见层和隐层的状态向量。ai,bj和Wij为三个实数参数,分别表示可见层i单元的偏置项,隐层j单元偏置项,可见层i单元和隐层j单元的连接权重。其中:

基于此能量函数,可以得到v和h的概率分布:

其中Z(θ)是归一化因子。
学习:
学习RBM的任务当然是求出最优参数θ,可以通过最大化在某个训练集上的对数似然函数来求得:

其中t是训练样本标记(t∈(1,T))T为训练样本总数。
其中L(Θ):

为了求最优Θ*,可以用随机梯度法求L(θ)的最大值,关键就是求梯度,即L(Θ)对各个参数的偏导数:

其中<.>P表示求关于P的分布。显然,第一项的边缘分布P(h|v(t),θ)是在训练样本已知的情况下求相对的隐层的分布,比较容易计算。第二项是联合分布,不容易求,但是可以通过Gibbs采样来逼近。值得指出的是在最大化似然函数的过程中,为加快速度,上述偏导数在每一迭代步中的计算一般只基于部分而非所有的训练样本进行。假设只有一个训练样本,对数似然函数对于三个参数Wij,ai和aj的偏导数:

其中data和model分别是对上面两项分布的简写。
Gibbs采样:
由于RBM模型的对称性及各层间神经元状态的独立性,可以用Gibbs采样得到服从RBM定义的分布的随机样本。在RBM中进行k步Gibbs采样的具体算法:用一个训练样本(或者可见层的任何随机化状态)初始化可见层状态v0,交替进行如下采样:

这样可以得到一个联合分布的近似。
基于对比散度(CD)的快速学习算法:
CD(Contrastive Divergence)法是Hiton在2002年提出的一个快速学习算法。不同于Gibbs采样,当使用训练数据初始化v0时,只需要k(通常k=1)步Gibbs采样即可得到足够好的近似。
算法基本流程如下:

参考文献:
1.
2. 张春霞, 姬楠楠, 王冠伟. 受限玻尔兹曼机简介.